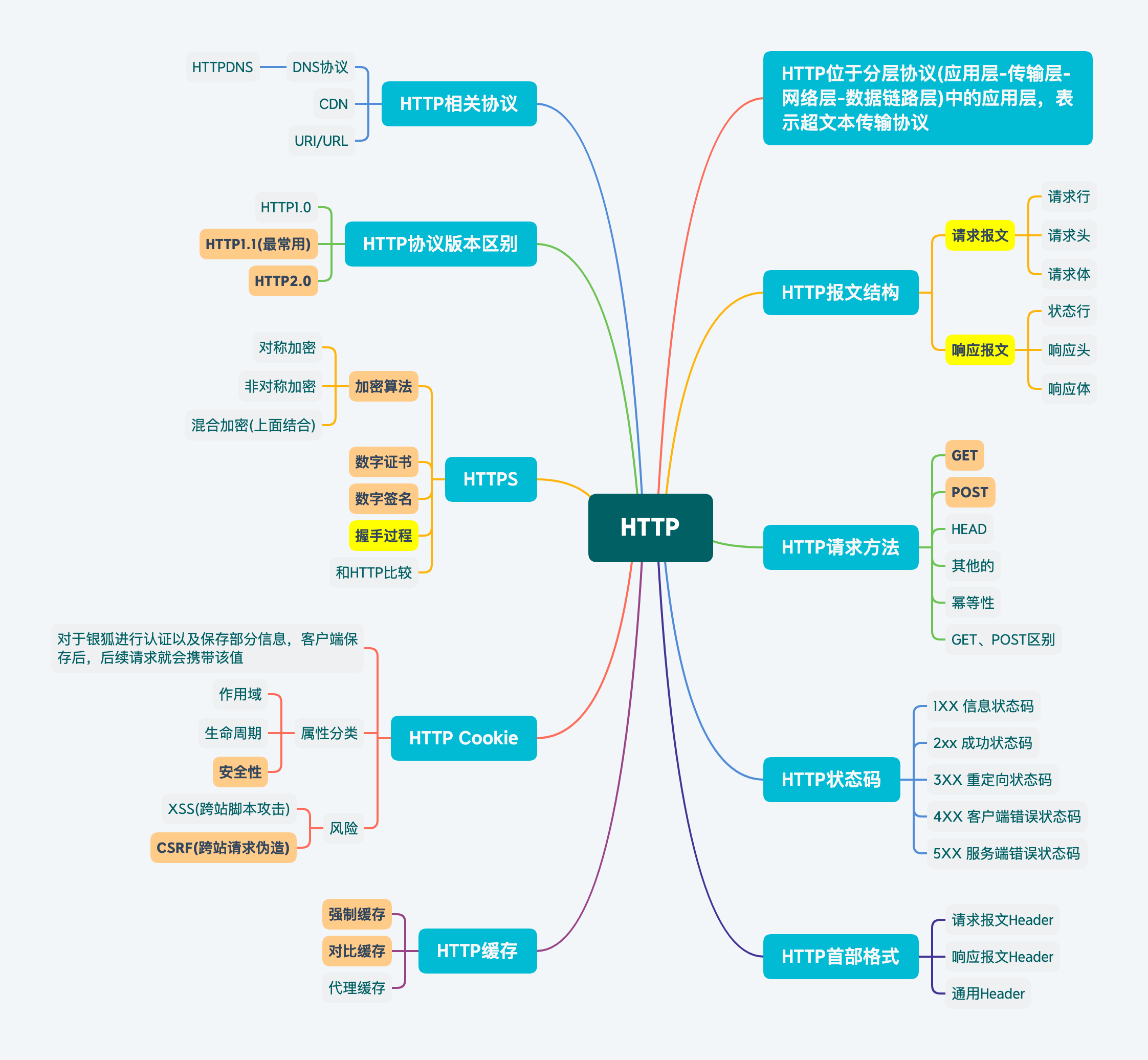
HTTP的原理和工作机制
HTTP的原理和工作机制
什么是HTTP?
HyperText(可以指向其他文本的链接文本) Transfer Protocol——超文本传输协议。位于
TCP/IP协议的最顶层——应用层。
从日常角度来说,在App中调用网络请求,直接就会使用到HTTP。发送数据(Request)到服务端,等待服务端数据处理完毕再返回(Response)到App,App在进行后续处理,例如页面展示等。
HTTP工作机制
浏览器输入地址后发生了什么?
- 浏览器向DNS服务器请求解析该url中的域名对应的IP地址
- 解析得到IP地址后,根据IP地址和端口,与服务器建立TCP连接
- 浏览器发出读取文件的HTTP请求
- 服务器对浏览器请求做出响应,返回html文本到浏览器
- 根据Header中的
Connection判断是否需要释放TCP连接,若为close则关闭连接;为keep-alive则保持该连接一段时间,可以继续接受服务器数据 - 浏览器解析服务端返回的html文本并显示
HTTP特点与缺点
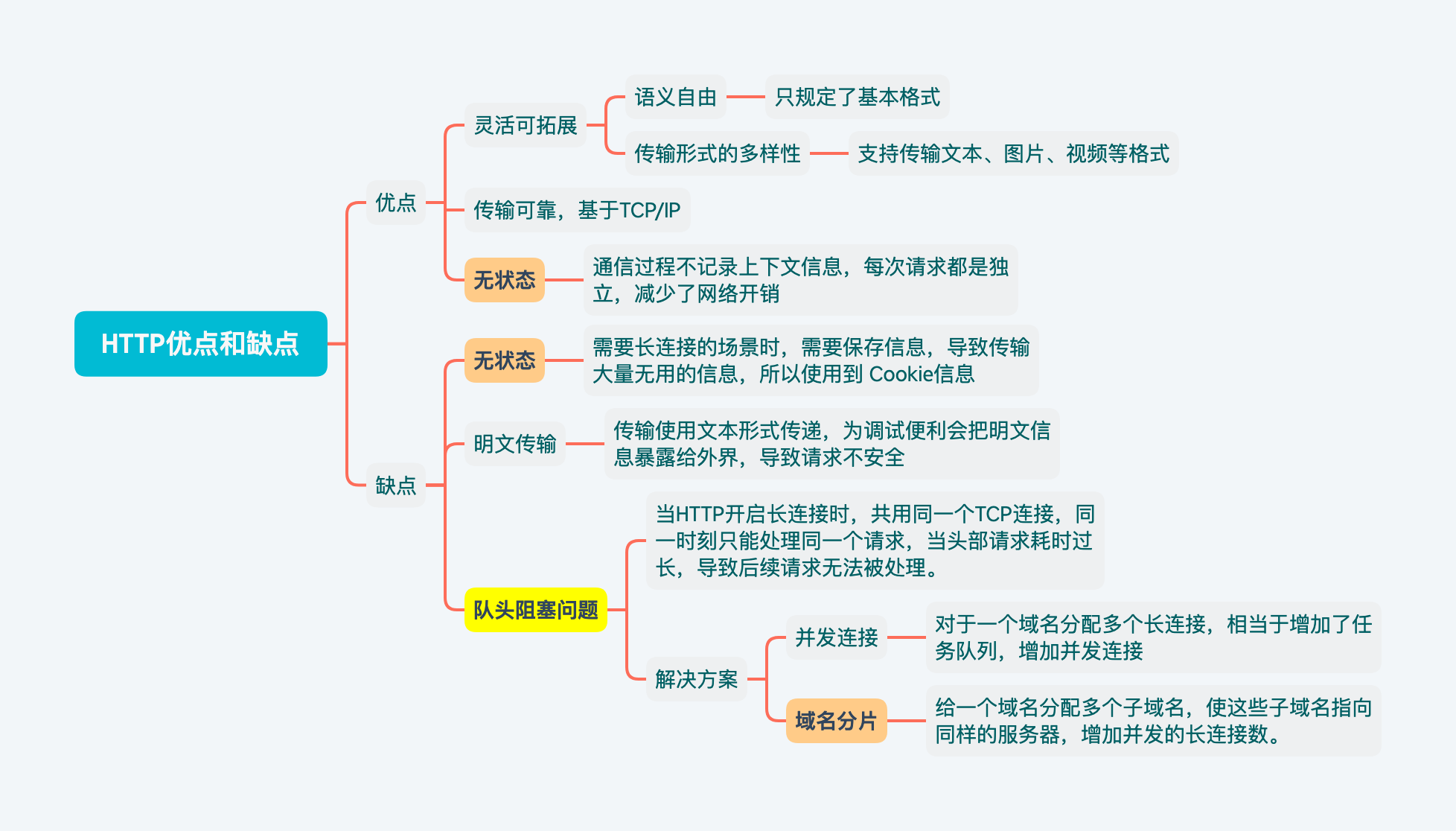
特点
- 灵活可拓展
- 只规定基本格式,没有语法的限制
- 传输形式多样性,支持文本、图片、视频等数据
- 传输可靠,基于TCP/IP,继承其特性
- 无状态,通信过程不会记录上下文信息,每次请求都是独立的,减少了网络开销
缺点
无状态
需要长连接的场景中,需要保存信息时,导致传输大量无用的信息,这时就是缺点
如果只是单纯的获取数据,不需要保存信息时,反而减少了网络开销
明文传输
协议里的报文使用文本形式传递,为调试提供便利但是会把明文信息暴露给外界,导致请求不安全。
队头阻塞问题
当http开启长连接时(
Connection:Keep-Alive),共用同一个TCP连接,同一时刻只能处理同一个请求,当头部请求耗时过长,会导致后续请求堵塞,产生队头阻塞问题。
HTTP报文结构
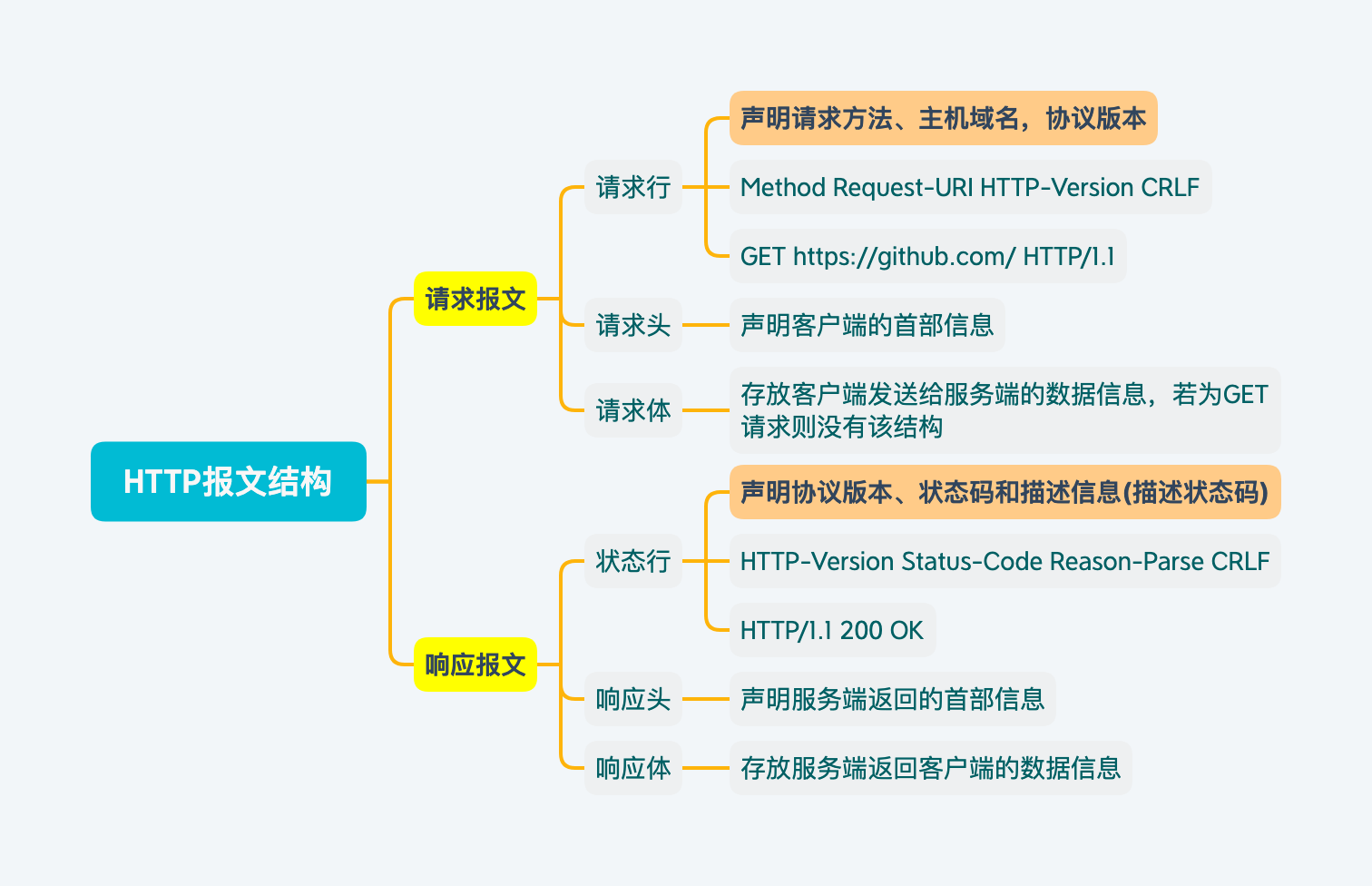
请求报文(Request)
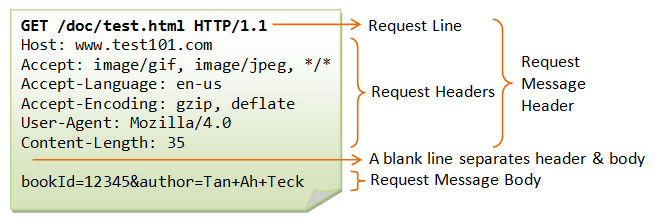
请求行
声明请求方法、主机域名和协议版本
基本格式: Method Request-URI HTTP-Version CRLF
Method:表示请求方法,例如GET、POST...
Request-URI:统一资源标识符,例如https://leo-wxy.github.io/
HTTP-Version:HTTP协议版本,例如HTTP/1.1 HTTP/2.0
CRLF:表示回车和换行,\r\n
示例数据: GET http://leo-wxy.github.io/ HTTP/1.1
请求头
声明客户端的首部信息
参考后面章节的 Headers
请求体
存放客户端发送给服务端的数据信息,若为
GET请求则没有该结构
参考后面章节的 Body
示例
| 请求行 | GET /test/index.html HTTP/1.1 |
|---|---|
| 请求头 | Host : www.github.io |
| User-Agent : Mozilla/5.0 | |
| 空行 | (用于隔开请求头和请求体) |
| 请求体 | id=0&page=1 |
响应报文(Response)
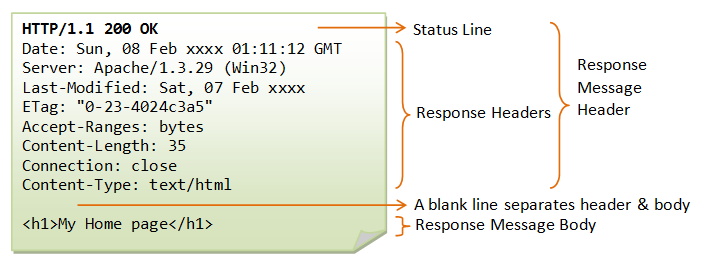
状态行
声明协议版本、状态码和描述(对状态码进行描述)
基本格式: HTTP-Version Status-Code Reason-Parse CRLF
HTTP-Version:HTTP协议版本,例如HTTP/1.1 HTTP/2.0
Status-Code:服务器返回的状态码,对应上面的响应状态码
Reason-Parse:状态码的文本描述,对应上面的响应状态码
CRLF:表示回车和换行,\r\n
示例数据: HTTP/1.1 404 Not Found
响应头
声明客户端、服务端的报头信息
参考后面章节的 Headers
响应报文
存放反给客户端的数据信息
参考后面章节的 Body
示例
| 状态行 | HTTP/1.1 200 OK |
|---|---|
| 响应报头 | Connection : keep-alive |
| Server : Nginx | |
| 空行 | (用于隔开响应头和响应正文) |
| 响应正文 | {“error”:false,”result”:1} |
HTTP Request Methods
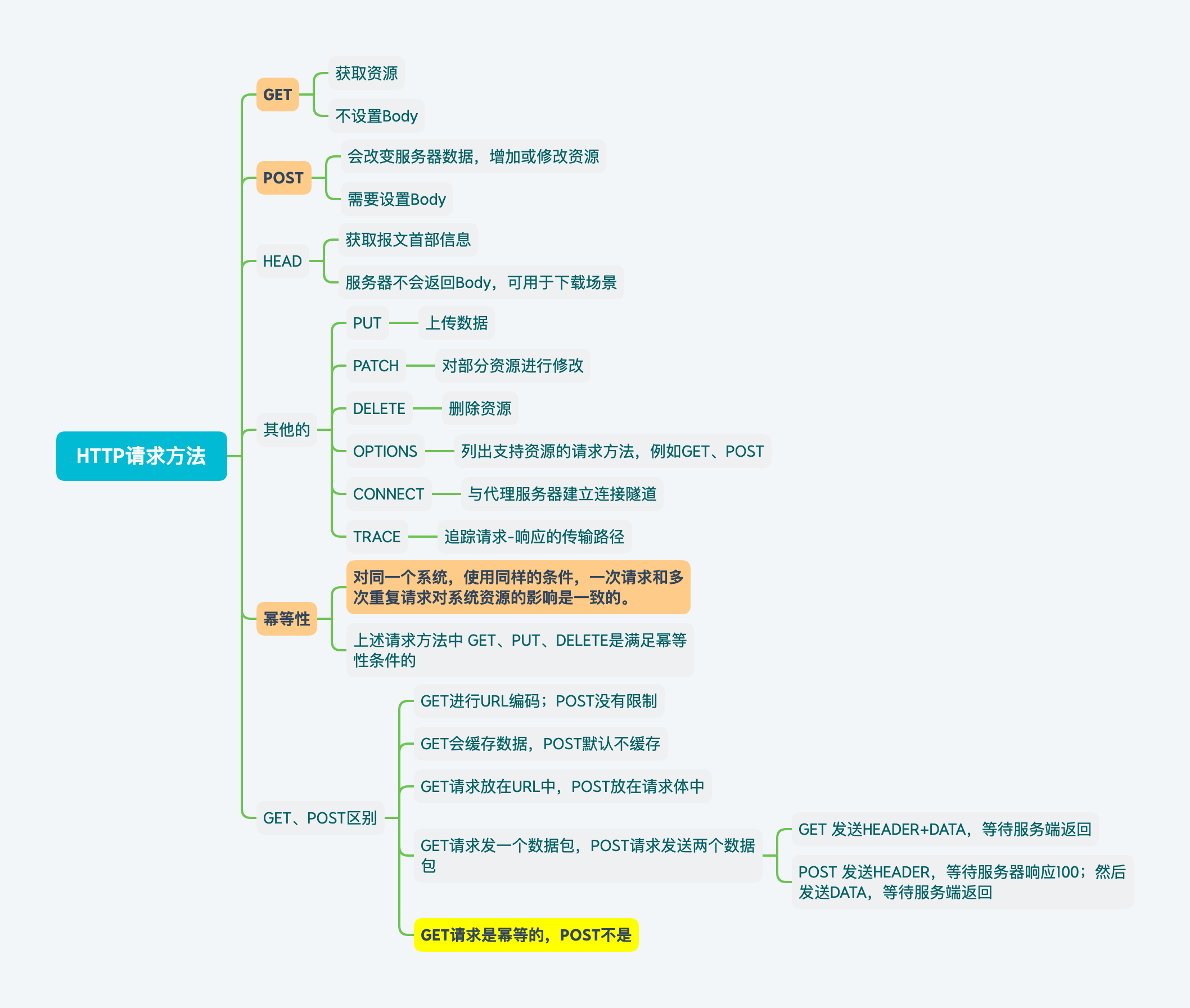
HTTP协议所定义的请求方法
| 请求方法 | 作用 | 描述 | 简化 |
|---|---|---|---|
| GET | 获取资源 | 客户端需要从服务器读取资源时使用 一般用于获取/查询信息 通过URL传递且参数长度是有限制的 请求格式 /test/result?key=key&page=1请求是安全的,因为只读,不会改变服务器数据 |
用于获取资源 不设置Body 不会改变服务器数据 符合幂等性 |
| POST | 传输实体主体 | 客户端向服务端提供信息时使用 可以附带数据,用于更新服务器数据 将请求参数封装在请求数据中,可传输大量数据 传参方式更加安全,但是请求是不安全的,会导致服务器数据发生改变 |
会改变服务器数据,增加或修改资源 需要设置Body 不符合幂等性 |
| HEAD | 获取报文首部 | 不返回报文实体部分,主要用于确认URL有效性以及资源更新日期 | 几乎与GET相同服务器不返回Body 可用于下载场景,获取信息 |
| PUT | 上传文件 | 自身不带验证机制,存在安全性问题。一般不使用 | 会改变服务器数据,只能修改资源 不设置Body 符合幂等性 |
| PATCH | 对资源部分进行修改 | 可以部分对资源进行修改 | |
| DELETE | 删除文件 | 自身不带验证机制,存在安全性问题。 | 会改变服务器数据,删除资源 不设置Body 符合幂等性 |
| OPTIONS | 查询支持的方法 | 查询指定的URL可以提供的方法。 返回示例: Allow: GET , POST |
|
| CONNECT | 要求与代理服务器通信时建立隧道 | 对通信内容进行加密后通过网络隧道传输 | |
| TRACE | 追踪路径 | 将通信路径返回给客户端 |
Tips
幂等性
对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。
HTTP请求方法中的GET、PUT、DELETE是满足幂等性的。
常见问题
GET和POST请求有什么区别?
- GET请求会被主动缓存下来,留下历史记录;POST不会缓存
- GET方式提交的数据长度有限制(URL长度限制),POST请求数据可以非常大
- GET请求只能进行URL编码;POST没有限制
- GET请求都是放在URL中的,安全性不高;POST可以放在请求体中,增强安全性
- (本质区别)GET请求是幂等的;POST不是
HTTP Status Code
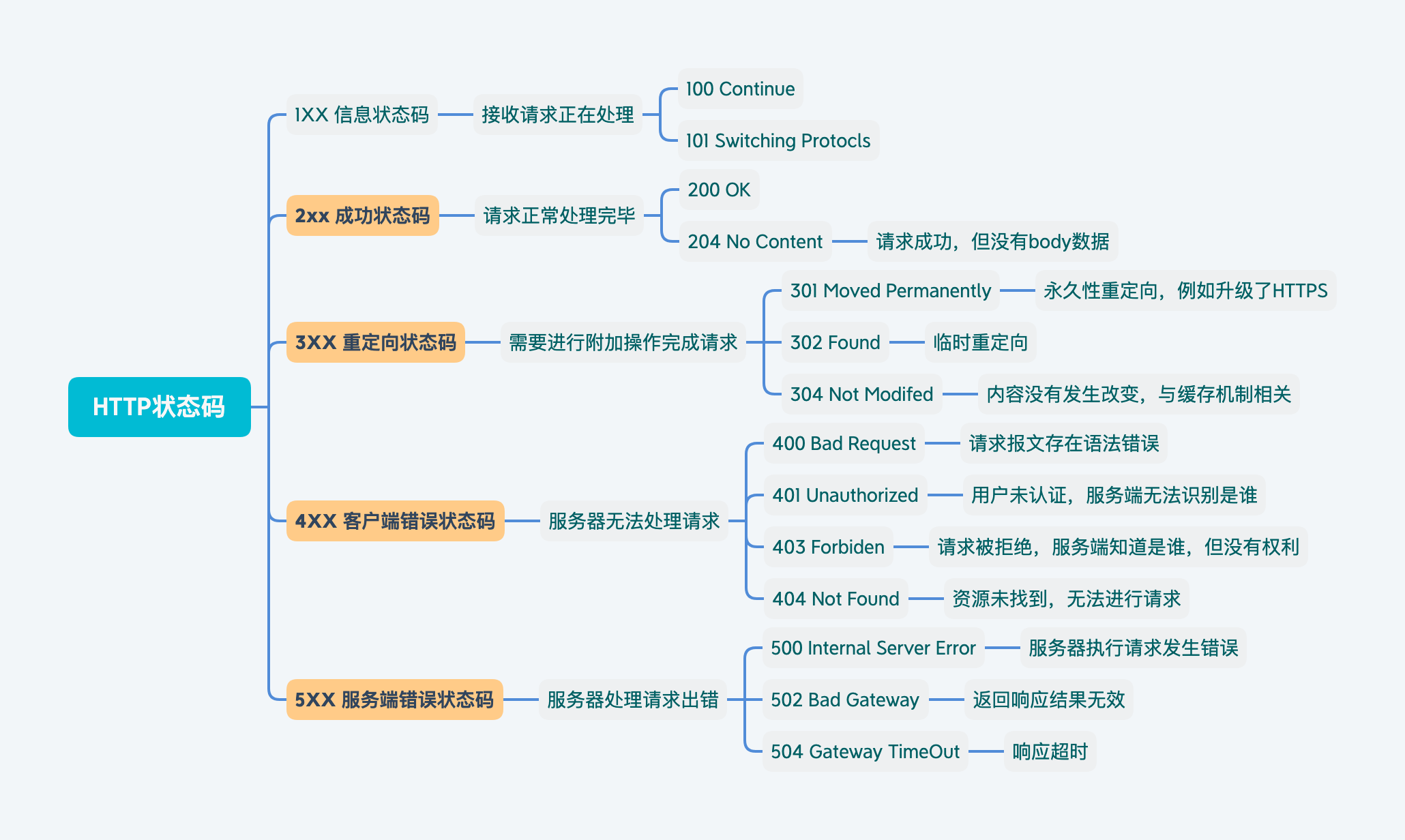
位于服务端返回响应报文中的第一行,包含了状态码以及原因短语,用来告知客户端请求结果。
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务端错误状态码) | 服务器处理请求出错 |
1XX 信息状态码
- 100 Continue:客户端继续发送请求
- 101 Switching Protocls:正在切换协议,可以切换HTTP 2.0
2XX 成功状态码
- 200 OK:请求成功
- 204 No Content:请求成功,但没有body数据
- 206 Partial Content:部分内容,用于分块下载和断点续传,与
Content-Range一起使用
3XX 重定向状态码
- 301 Moved Permanently:永久性重定向 常见
- 302 Found:临时性重定向
- 304 Not Modified:内容没有改变,与Http缓存有关
4XX 客户端错误状态码
- 400 Bad Request:请求报文存在语法错误
- 401 Unauthorized:未认证用户-
服务端不知道你是谁 - 403 Forbiden:请求被拒绝-
服务端知道你是谁,但你不配 - 404 Not Found:找不到对应服务器
5XX 服务端错误状态码
- 500 Internal Server Error:服务器执行请求发生错误
- 502 Bad Gateway:返回响应无效
- 503 Server Unavliable:服务器无法处理请求
- 504 Gateway Time-out:服务器处理请求超时
HTTP Header
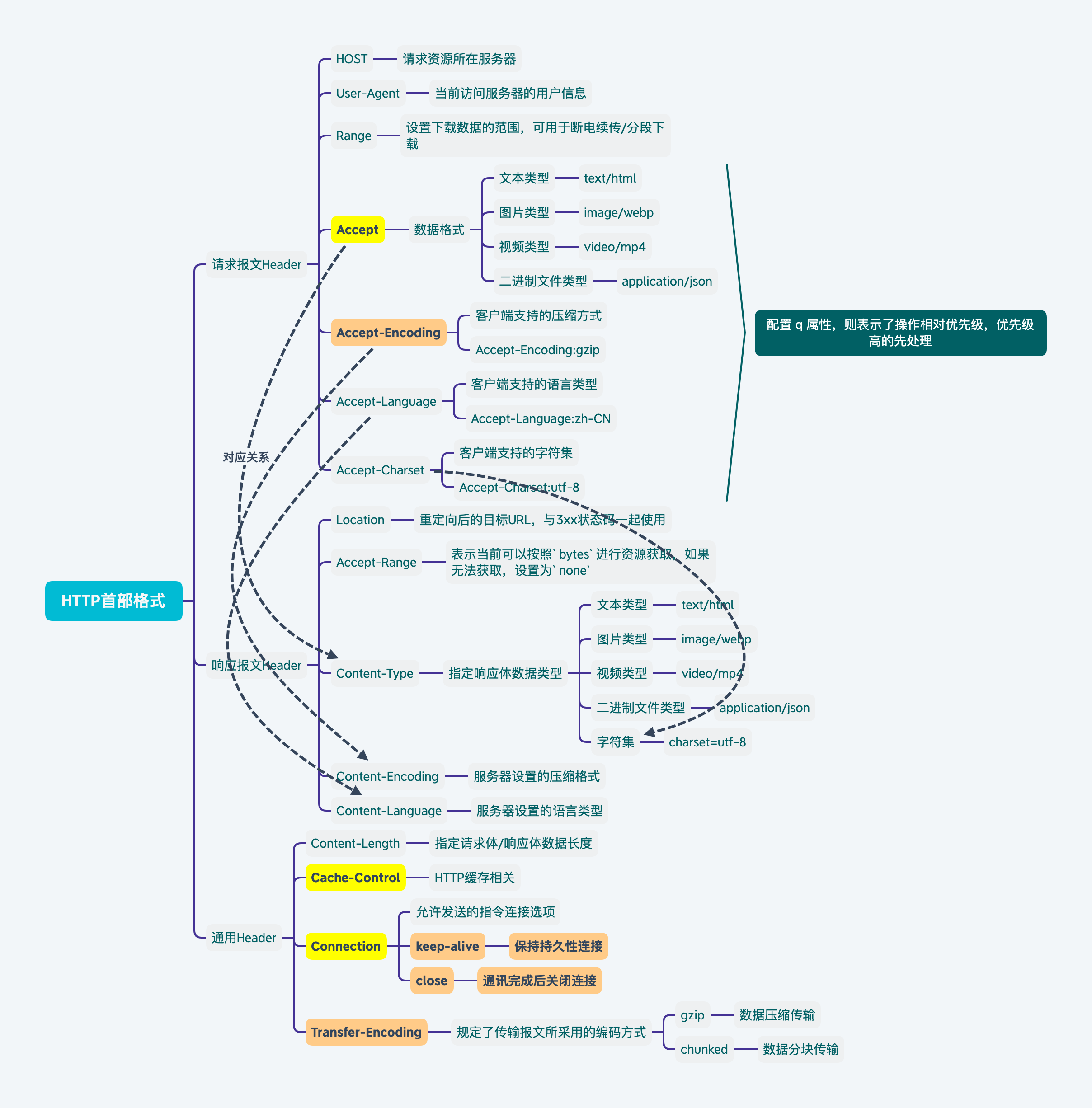
HTTP消息的元数据(metadata),例如消息长度、格式等。
请求报文Header
Accept:客户端可以接受的MIME类型
MIME类型:描述消息内容类型的因特网标准,包含文本、图像、音频、视频以及其他应用 程序专用数据,例如PDF之类的
文本类型:text/html、text/css
图片文件:image/gif、image/png
视频文件:video/mpeg、video/mp4
应用程序二进制文件:application/json、application/pdf
如果Accept包含了某类型,表示客户端可以支持该格式数据处理。
一般MIME类型会和q这个属性一起使用,
例如Accept:text/html,application/json;q=0.9,image/webp;q=0.8,*/*;q=0.8
q表示了媒体类型增加优先级,权重高的优先处理。
例如上述数据表示:
| 权重 | MIME类型 |
|---|---|
| 1.0 | text/html |
| 0.9 | application/json |
| 0.8 | Image/webp |
Accept-Encoding:支持的压缩方式
一般都会对传输数据进行编码压缩,设置客户端可接受的压缩方式
gzip:由文件压缩gzip程序产生的编码格式 最常用
deflate:使用zlib结构和deflate算法产生的压缩格式
br:使用Brotil算法的压缩格式
如果配置了q,也表示相对优先级,例如Accept-Encoding:gzip;q=0.9
Accept-Language:支持的语言
指定客户端支持的语言
如果配置了q,也表示相对优先级,例如Accept-Language:zh-CN;q=0.9
Accept-Charset:支持的字符集
指定客户端支持的字符集
如果配置了q,也表示相对优先级,例如Accept-Charset:utf-8;q=0.9
Host:请求资源所在服务器
User-Agent:当前访问服务器的用户信息
Range:设置下载数据的范围,可用于断点续传/多线程下载。
响应报文Header
Location:重定向后的目标url
Accept-Range:表示当前可以按照bytes来进行资源获取
Content-Type:指定请求体(Body)类型/响应体返回数据类型
text/html:返回Html文本application/json、image/jpeg:返回文本或文件内容,也可用于向服务器传输文件application/x-www-form-urlencoded:普通表单类型提交,只支持传文本multitype/form-data:支持提交二进制文件,例如图片啥的charset=utf-8:表示设置的字符集 对标于Accept-Charset
Content-Encoding:服务端设置的压缩格式 对标于Accept-Encoding
Content-Language:服务端设置的语言 对标于Accept-Language
通用Header(请求/响应都可以用)
Content-Length:指定请求体(Body)长度/响应体返回数据长度
Connection:允许发送的指令连接选项
keep-alive:保持连接close:通讯完成后关闭连接
Cache-Control:对数据进行缓存,减少从服务器获取数据次数,优化网络性能
no-cache:需要使用到对比缓存no-store:不要缓存数据max-age:XX:缓存在XX时间后失效private:客户端可以缓存数据(个人化信息)public:客户端与中间节点都可以进行缓存(所有人都能使用)s-maxage:限定缓存在代理服务器中可以存放多久
HTTP Cache
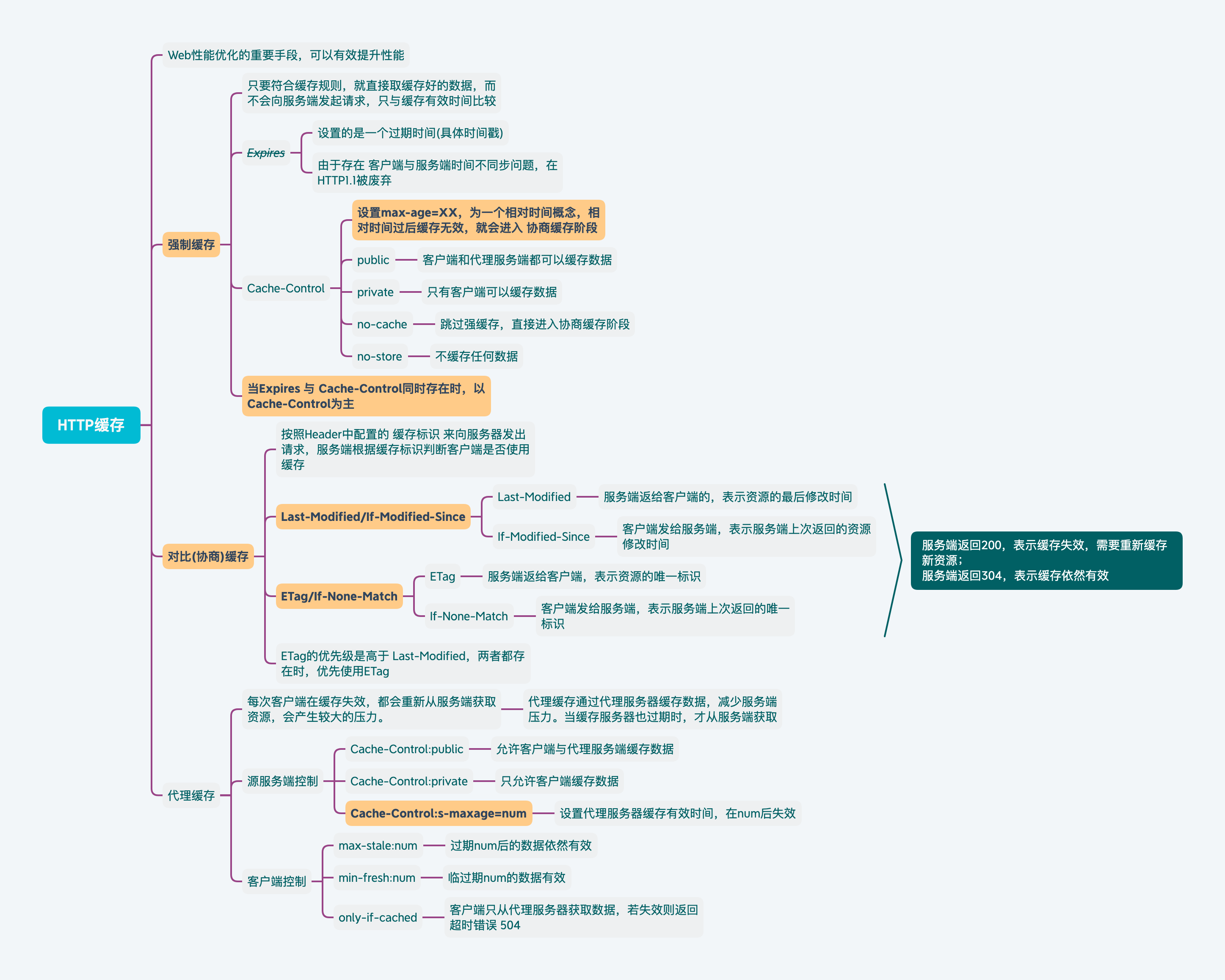
Web性能优化的重要手段,主要依赖于上节中配置的
Header。会去指定缓存的来源
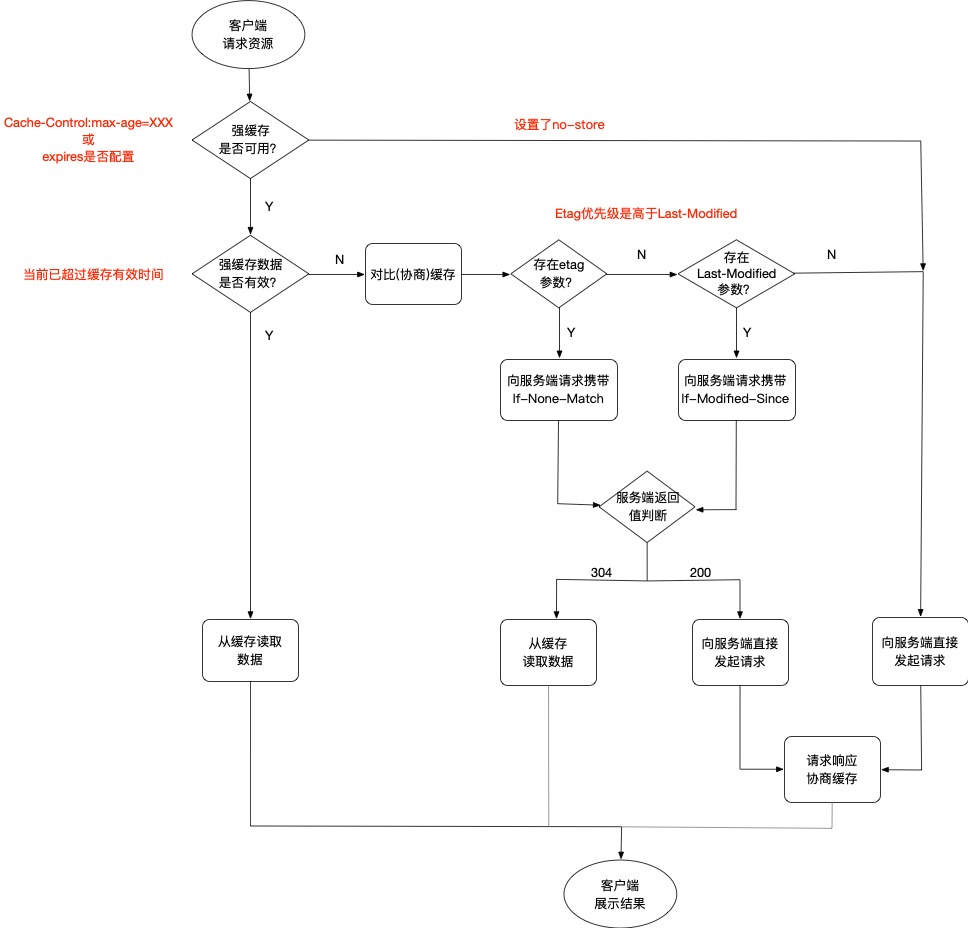
强制缓存
在第一次请求数据时,服务端在Header会携带
缓存规则信息,只要符合缓存规则,就直接取缓存数据,不会重新发起请求。按照服务端给予的缓存时间比较,不超出则一直使用缓存数据。
通过Cache-Control验证强缓存是否可用,如果设置了max-age=XXX,表示缓存会在XXX后的时间失效,在这期间只要请求资源,都会从缓存中获取数据。
在HTTP1.0版本使用的是Expires字段,存放的是一个具体的过期时间,但是存在服务器与客户端时间不同步问题,导致缓存失效时间无法确定。所以在HTTP1.1是废弃了该字段。
对比缓存
需要按照
Header中的配置来判断是否需要读取缓存还是重新从服务器中拉取数据。
按照缓存下来的数据标识,需要每次与服务器进行交互去验证缓存标识是否有效,有效则继续使用缓存数据即可。
以下则为认证时用到的缓存标识:
Last-Modified/If-Modified-Since
Last-Modified:服务端返回给客户端,表示资源的最后修改时间If-Modified-Since:客户端发送服务端,表示服务端返回的上次资源修改时间
服务端在收到If-Modified-Since之后,与服务端资源进行比较
- 若本地时间大于接收的时间,则返回
200,需要客户端重新缓存资源 - 否则,返回
304,表示资源没有发生变化,客户端可以继续使用本地缓存资源
ETag/If-None-Match
ETag:服务端返回给客户端,表示当前资源在服务器的唯一标识If-None-Match:客户端发送给服务端,表示服务端说返回的资源唯一标识
服务端在收到If-None-Match之后,进行服务器资源的唯一标识比对
- 标识不一致,返回
200,需要客户端重新缓存资源 - 否则,返回
304,客户端可以继续使用本地缓存资源
强制缓存的优先级是高于对比缓存的。
Etag/If-None-Match这组标识符的优先级是高于Last-Modified/If-Modified-Since,如果存在则优先执行。
代理缓存
每次客户端缓存失效都需要从源服务器获取的话,会产生较大的压力。所以引入
代理缓存机制,由代理服务器进行数据的缓存,但代理服务器缓存过期了才从源服务器请求数据。
缓存代理的控制分为两部分:源服务端的控制,客户端的控制。
源服务端的控制
通过配置Cache-Control属性进行控制
Cache-Control:public:允许代理服务器进行缓存
Cache-Control:private:只允许客户端进行缓存
Cache-Control:s-maxage=XXX:允许缓存服务器最多缓存XXX时间
与max-age的区别是,max-age管理的是客户端的缓存有效时间。
客户端的控制
通过在请求头配置属性进行控制
max-stale:num:表示客户端在代理服务器拿到缓存时,最多允许num的过期时间
min-fresh:num:表示代理缓存在到期num秒之前可以获取
only-if-cached:表示客户端只从代理缓存获取数据,获取缓存无效则返回504超时
HTTP Cookie
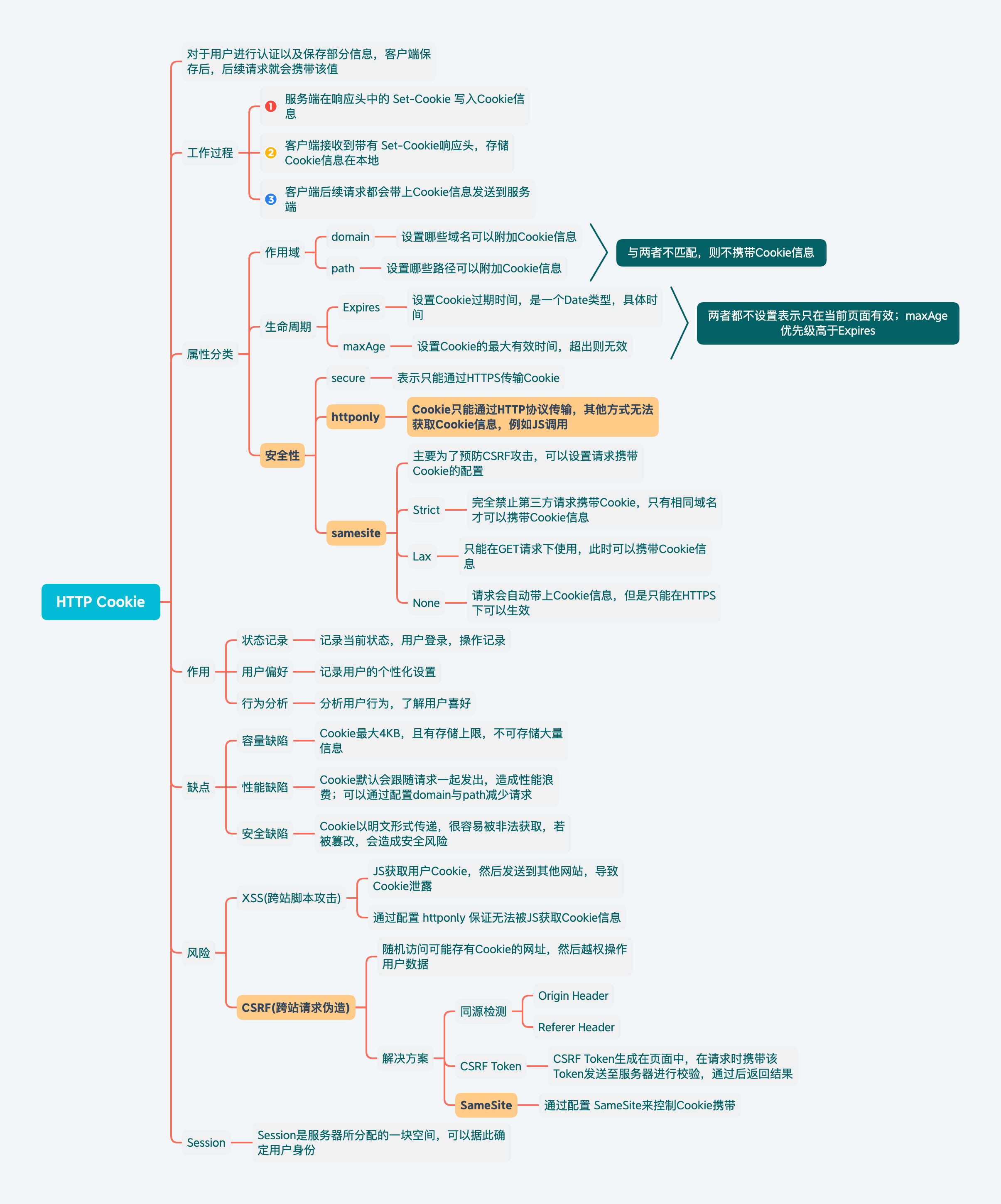
由于HTTP协议是无状态的,不对之前发生的请求和响应进行管理。Cookie就是为了解决这类问题所提供的。可以用于对用户进行认证以及保存部分信息。客户端保存本地后,后续请求就会带上该信息。
Cookie会根据从服务端发送的响应报文(Response)内的一个叫做Set-Cookie的Header信息,通知客户端保存Cookie信息。当下次再发起请求时,客户端会自动在请求报文(Request)中加入Cookie值后发送到服务端。

属性
| 属性 | 类型 | 描述 |
|---|---|---|
| domain | String | 指定浏览器发出HTTP请求时,哪些域名需要附加Cookie信息 |
| expires | Date | 指定一个具体的Cookie到期时间,值为UTC格式 |
| httponly | Boolean | 指定该无法通过JS脚本拿到,主要是Document.cookie获取 |
| maxAge | String | 指定从现在开始的Cookie存在秒数,超过则失效 |
| path | String | 指定浏览器发出Http请求时,哪些路径要附带这个Cookie信息 |
| secure | Boolean | 指定浏览器只有在HTTPS协议下可以发送Cookie到服务器 |
| signed | Boolean | 给浏览器发送一个加密的Cookie,服务端可以校验该Cookie是否被篡改 |
| SameSite | String | 设置第三方Cookie属性 |
按照功能可以将以上7个属性进行分类
Cookie生命周期-expires,maxAge
expires设置的是一个Date格式的时间,maxAge设置的是一个毫秒时间戳。推荐使用maxAge
若同时指定了expires和maxAge,那么maxAge属性优先生效。
若不设置任一属性的值,那么该Cookie仅在当前页面生效,关闭就不会再保留。
Cookie作用域-domain,path
domain设置哪些域名需要附加Cookie信息,path设置哪些路径需要附加Cookie信息(若path:'/'表示该域名下所有路径都附加Cookie信息)。
若与任一属性值不匹配,那么请求服务端时就不会带上Cookie信息。
Cookie安全性-secure,httponly,SameSite
secure设置只有在HTTPS协议下可以传输Cookie;httponly设置Cookie只能通过HTTP协议进行传输,其他方式都无法获取Cookie信息。
SameSite主要为了预防CSRF攻击,可以设置为3个值:
- None:显式关闭SameSite属性,但是必须设置
secure:true,否则设置无效 - Lax:只能在
GET请求下使用,请求时会携带Cookie,否则不会有信息 - Strict:浏览器完全禁止第三方请求携带Cookie信息,只能在同一域名下生效。
作用
- 状态记录:记录当前状态,例如用户登录,操作记录
- 用户偏好:记录用户的个性化设置
- 行为分析:分析用户的行为,可以了解用户喜好
缺点
- 容量缺陷:Cookie保存的诗句不能超过4K,而且浏览器会设置保存Cookie的上限
- 性能缺陷:Cookie默认跟随域名一起发起请求,无论需要与否,导致性能浪费。可以通过设置
domain和path减少使用。 - 安全权限:Cookie以纯文本形式进行传递,很容易被非法截获,然后进行篡改后再发给服务端,降低安全性。
风险
XSS(跨站脚本攻击):被JavaScript获取用户Cookie,然后发送到其他网站,就会导致Cookie泄漏,危害数据安全。
解决方案:在Cookie信息中添加
HttpOnly属性,就保证当前Cookie只会用于网络请求,而不会被获取。CSRF(跨站请求伪造):随机访问可能存有Cookie的网址,然后越权操作用户数据。
解决方案:
同源检测
使用
Origin Header确定来源域名使用
Referer Header确定来源域名
CSRF Token
SameSite Cookie属性
HTTPS
是以安全为目标的HTTP通信,在HTTP下加入了SSL/TLS协议,用于保障HTTP的加密传输。
TLS(传输层安全性协议):前身为SSL(安全套接层),目的是为互联网通信提供安全及数据完整性保障。使用
SSL后,HTTPS就具有加密、认证,完整性保护功能
HTTPS加密
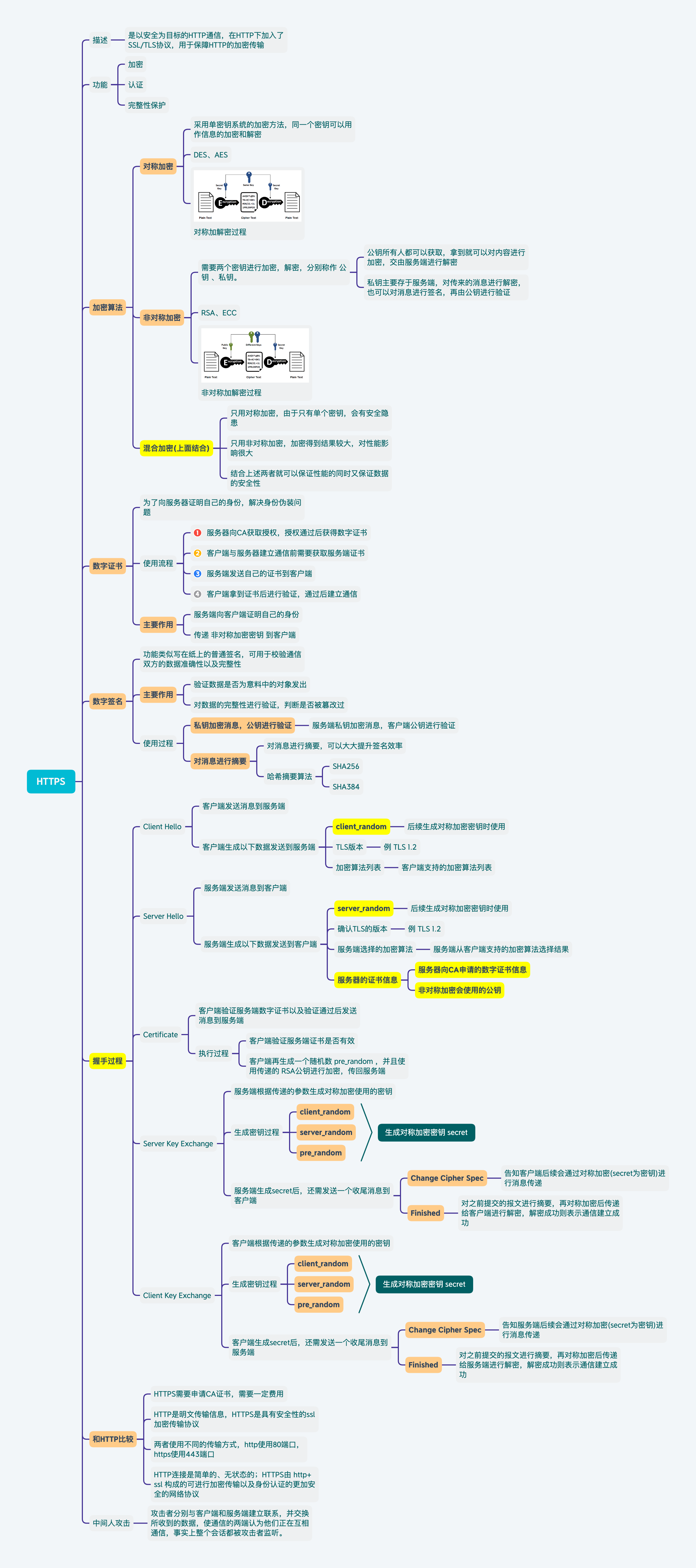
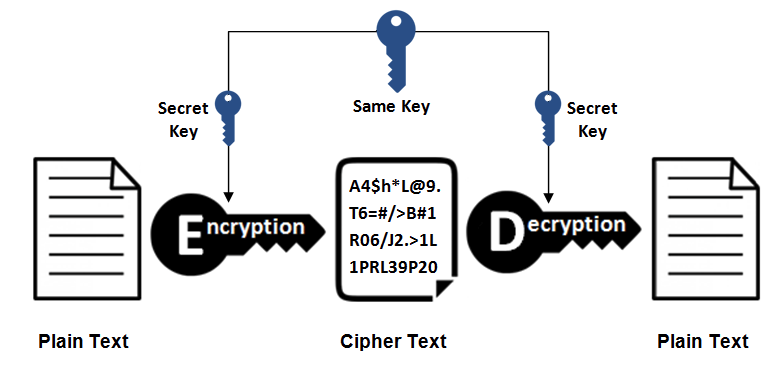
对称密钥加密
采用单钥密码系统的加密方法,同一个密钥可以用作信息的加密和解密。
也可叫
单密钥加密。
常用加密算法
DES、AES
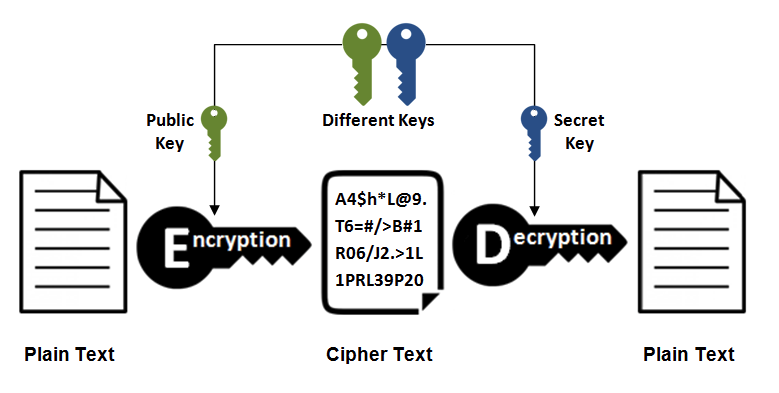
非对称密钥加密
需要两个密钥来进行加密和解密,这两个密钥分别是公钥(public key)和私钥(private key)。
公钥所有人都可以获得,通信方得到公钥后,就可以对发送内容进行加密,然后传递至服务端,服务端就可以利用私钥进行解密。
私钥还可以对服务端返回内容进行签名,利用公钥去验证签名是否正确,防止被人篡改。
常用加密算法
RSA,ECC
混合加密(HTTPS采用方案)
采用了对称加密与非对称加密混合加密的形式,只用对称加密,会有安全隐患;只用非对称加密,性能消耗太大。所以需要结合两者,保证性能的同时又保证安全。
- 客户端向服务器发送
client_random和加密方法列表(例如RSA方法) - 服务端收到后,返回
server_random、加密方法(RSA)以及非对称加密公钥到客户端 - 客户端收到后,再生成一个
pre_random,使用非对称加密公钥加密后发送给服务器 - 服务端使用
非对称加密私钥解密后,得到的就是对称加密用到的密钥 - 双方持有
对称加密用到的密钥后,后续数据通信就用对称加密的方式进行。
本质就是为了防止私钥加密的数据外传。
数字证书(解决身份伪装问题)
为了向服务器证明自己的身份,可以解决身份伪装问题。
上面两种加密方式的结合,可以实现加密传输。但是还会存在一些问题,若发生了DNS劫持,那么传输过程中的所有内容都有可能造假,不能保证安全性。
数字证书的使用流程大概如下:
- 服务器首先向一个大家都信任的第三方机构(
CA)获取授权,获取通过后获取数字证书。 - 客户端向服务器建立通信之前向服务器请求获得服务器的证书
- 服务器收到请求之后发送数字证书给客户端
- 客户端获得证书之后,向第三方机构进行验证,验证通过后进行正常的内容通信。
数字证书有两个作用:
- 服务器向客户端证明自己的身份
- 把
非对称加密公钥传给客户端
CA机构
证书颁发机构。是负责发放和管理数字证书的权威机构,并作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
数字签名(解决数据篡改问题)
功能类似写在纸上的普通签名,可以用于校验通信双方数据的准确性以及完整性。
数字签名有两个作用:
- 验证数据是否为意料中的对象发出
- 对数据的完整性进行验证,验证数据是否被篡改过
使用私钥加密(生成签名),公钥解密(验证签名)。
服务端对消息进行私钥加密,客户端使用服务端传递的公钥进行验证,验证通过则表示消息一致,数字签名是正确的。
通常会对消息进行摘要,然后拿到消息的Hash值再进行私钥签名(Hash值一般都会小于消息原文),大大提升签名效率。
哈希摘要算法:根据任意长度数据计算出固定签名长度的算法。常用的有SHA256、SHA384。
握手过程
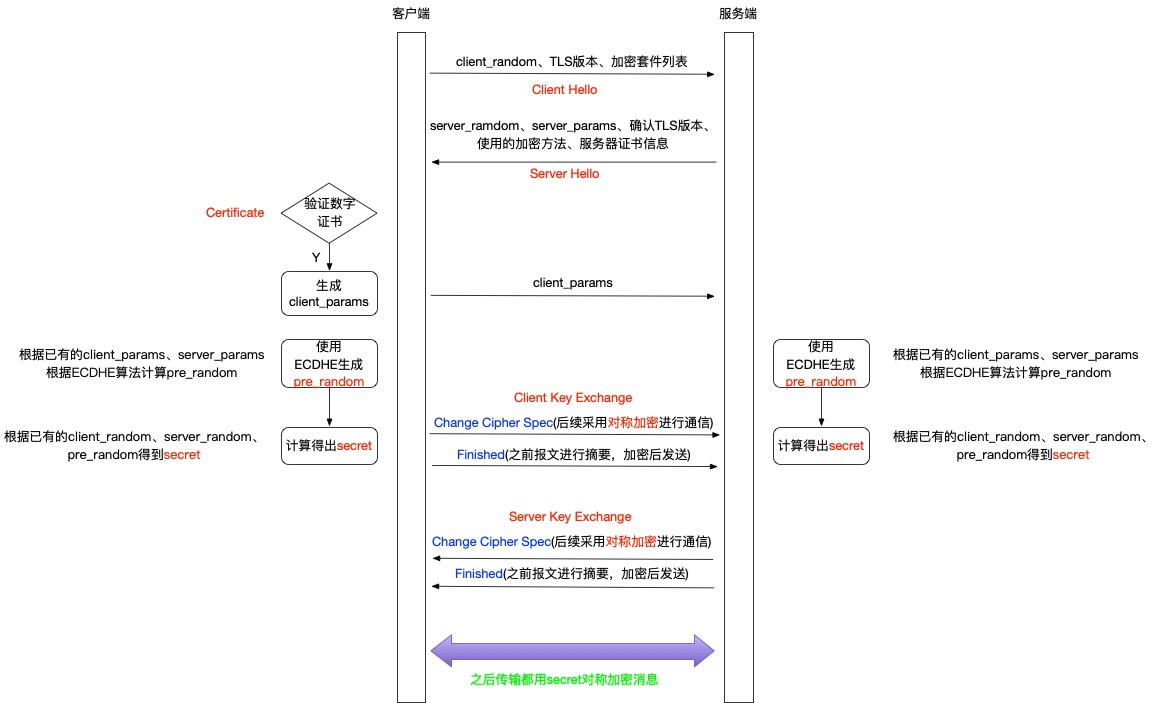
Client Hello
客户端发送消息到服务端
客户端生成随机数client_random,然后发送TLS版本,加密算法列表发送给服务端。
例如:发送消息为
Random:client_randomVersion:TLS 1.2Cipher Suites:TLS_AES_128_GCM_SHA256(只是其中一种,整体是一个List型)服务端会从列表中选择一种加密算法,后续使用该算法进行通信。
Server Hello
服务端发送消息到客户端
服务端同样生成随机数server_random,以及确认的TLS版本 、服务端选择的加密算法,服务器的证书信息返回给客户端。
例如:返回消息为
Random:server_randomCipher Suite:TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256(返回一个来确定后续都用这种加密方式)- ECDHE:密钥协商算法
- RSA:证书公钥加密算法
- AES_128:对称加密算法以及密法长度
- GCM:AES加密模式
- SHA256:消息摘要算法
Certificate:返回的服务端证书信息,以及非对称加密使用的公钥
Certificate
客户端验证数字证书以及验证通过后发送消息到服务端
客户端验证服务端传来证书和签名是否通过,如果通过,按照协议不同有以下两种处理方式
传统RSA版本
客户端再生成一个随机数
pre_random,并且使用证书携带的RSA公钥加密,传给服务端TLS 1.2版本
客户端生产
client_params参数给服务端
Server Key Exchange
服务端根据传递的参数生成对称加密使用的密钥
传统RSA版本
服务端接收到客户端传来的
pre_random,使用私钥进行解密,然后拿着client_random、server_random以及pre_random按照约定算法生成最终的secret(对称加密密钥)TLS 1.2版本
服务端接收到客户端传来的
client_params,使用ECDHE(椭圆曲线加密),根据已有的client_params和server_params生成最后的pre_random,最后使用client_random、server_random以及pre_random按照约定算法生成最终的secret(对称加密密钥)
服务端生成secret后,给客户端发送一个收尾消息,该收尾消息包含两部分:
Change Cipher Spec:提示客户端后续消息会采用secret的对称加密进行传递Finished:对之前报文的所有数据进行摘要,加密后交由客户端进行解密,解密通过则表示协商成功
Client Key Exchange
客户端根据已有的参数生成对称加密使用的密钥
传统RSA版本
客户端根据已有的
client_random、server_random以及pre_random按照约定算法生成最终的secret(对称加密密钥)TLS 1.2版本
客户端通过
ECDHE算法计算出pre_random,其中传入两个参数:server_params和client_params。现在你应该清楚这个两个参数的作用了吧,由于ECDHE基于椭圆曲线离散对数,这两个参数也称作椭圆曲线的公钥。客户端根据
client_random、server_random以及pre_random按照约定算法生成最终的secret(对称加密密钥)。
客户端生成secret后,会给服务端发送一个收尾消息,该收尾消息包含两部分:
Change Cipher Spec:提示服务器后续消息会采用secret的对称加密进行传递Finished:对之前报文的所有数据进行摘要,加密后交由服务端进行解密,解密通过则表示协商成功
当客户端与服务端都收到finished消息后,客户端和服务端都会持有secret,后续的请求都会使用secret进行对称加密传递消息。
HTTPS缺点
- HTTPS协议握手阶段比较费时,因为需要加密/解密过程
- SSL证书是需要收费
- HTTPS加密范围有限,而且证书不一定是可以信任的
与HTTP区别
- https协议需要向
CA申请证书,需要一定费用 - http信息是明文传输,HTTPS具有安全性的ssl加密传输协议
- http和https使用的是完全不同的连接方式,端口不同,http使用了
80端口,https使用443端口 - http连接是简单的,无状态的;HTTPS由
http+ssl构成的可进行加密传输,身份认证的网络协议,更加安全。
中间人攻击
攻击者与通信两端(服务端与客户端)分别创建独立的联系,并交换所受到的数据,使通信的两端认为他们正在通过一个私密的连接与对方直接通信,事实上整个会话都被攻击者完全控制、
中间人攻击者可以拦截通讯双方的通话并插入新的内容。
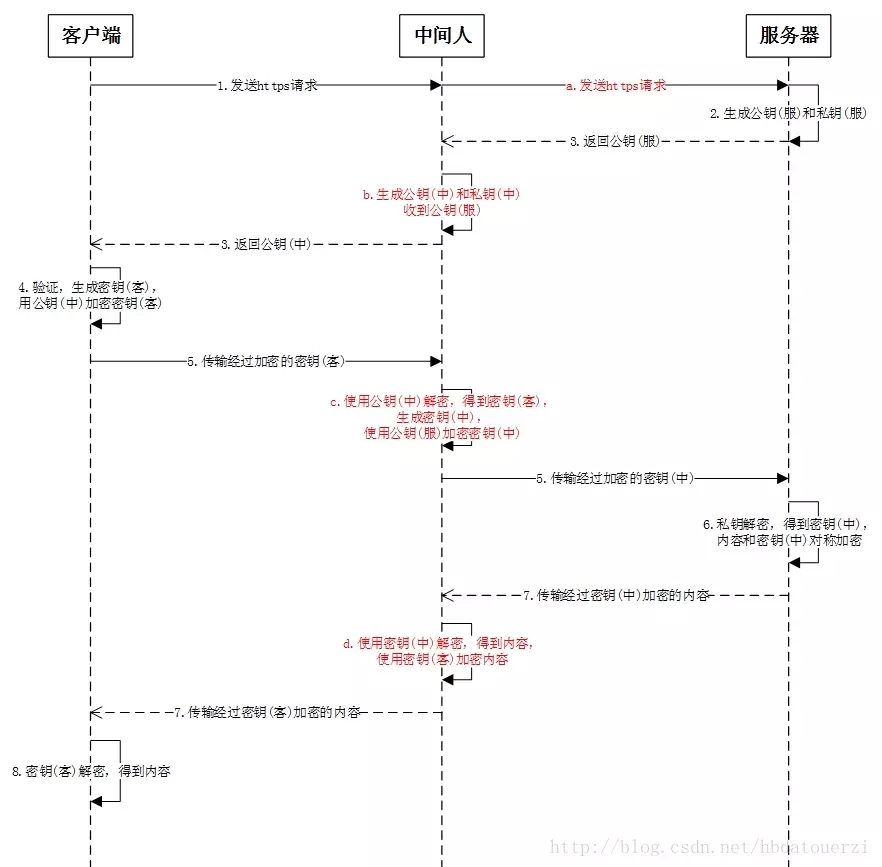
如何防御中间人攻击?
公钥基础建设PKI
PKI相互认证机制,服务端验证客户端,客户端验证服务端
使用复杂加密哈希函数运行计算以造成数十秒的延迟
如果双方通信时间过长,可以基本判断存在中间人
HTTP协议版本区别
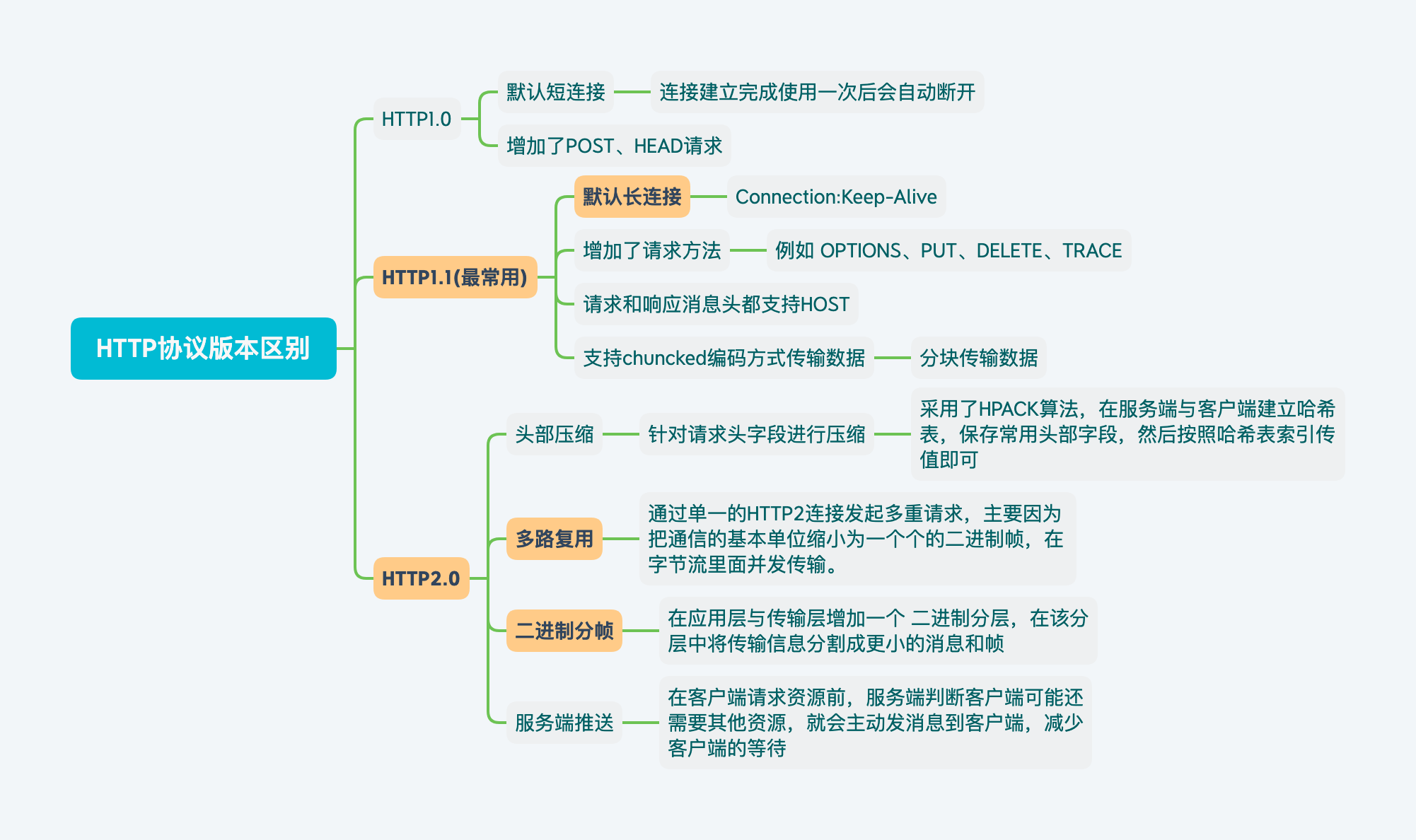
HTTP1.0
- 默认短连接
- 增加了POST、HEAD命令
HTTP1.1
- 默认长连接(默认添加Header
Connection:Keep-Alive) - 增加了请求方法(
OPTIONS、PUT、DELETE、TRACE、CONNECT) - 请求消息和响应消息都支持Host头域
- 支持chunked编码传输
HTTP2.0
头部压缩
针对请求头字段进行压缩,采用了
HPACK算法HPACK算法:
- 在服务端与客户端建立哈希表,存放使用的字段,只要在传输过程传输索引值,然后按照索引表查询即可
- 对于整数和字符串进行哈夫曼编码
多路复用
允许同时通过单一的HTTP2连接发起多重请求,由于把HTTP通信的基本单位缩小为一个个的二进制帧,各自对应着信息。
被拆分为很多互不依赖的
二进制帧后,这些二进制帧就可以乱序发送。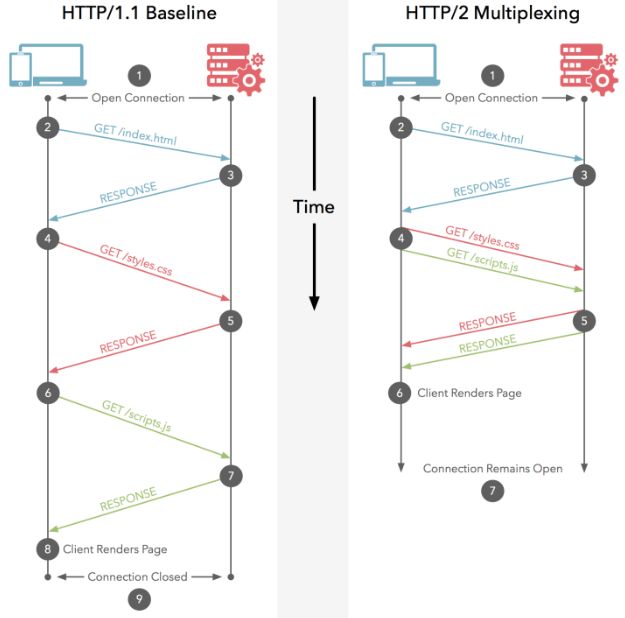
二进制分帧
HTTP/2在 应用层和传输层增加一个
二进制分层,在该分层中将传输的信息分割为更小的消息和帧,并采用二进制格式的编码。HTTP队头阻塞:在同一个TCP长连接中,前面的请求没有得到响应的话,后面的请求就无法被处理,导致阻塞。
并发连接:对于一个域名分配多个长连接,相当于增加了任务队列,可以分散任务。域名分片:对一个域名分配多个二级域名,但是指向同一台服务器,使并发变多。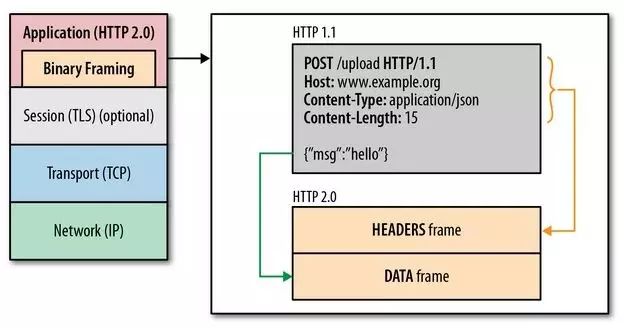
服务端推送
在客户端请求之前发送数据,客户端请求一个资源后,服务端判断可能还需要其他资源,就会主动发送消息到客户端,减少客户端的等待
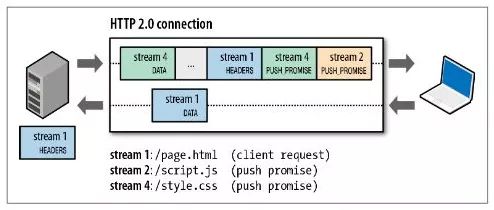
需要注意以下两点:
- 服务端推送遵循
同源策略 - 服务端推送基于客户端的请求响应来确定的
当服务端需要主动推送某个资源时,便会发送一个
PUSH_PROMISE的二进制帧(Frame),里面携带了Stream ID,表示服务端会用这个ID来推送资源,客户端解析时,需要从这个ID获取资源。- 服务端推送遵循
HTTP相关协议
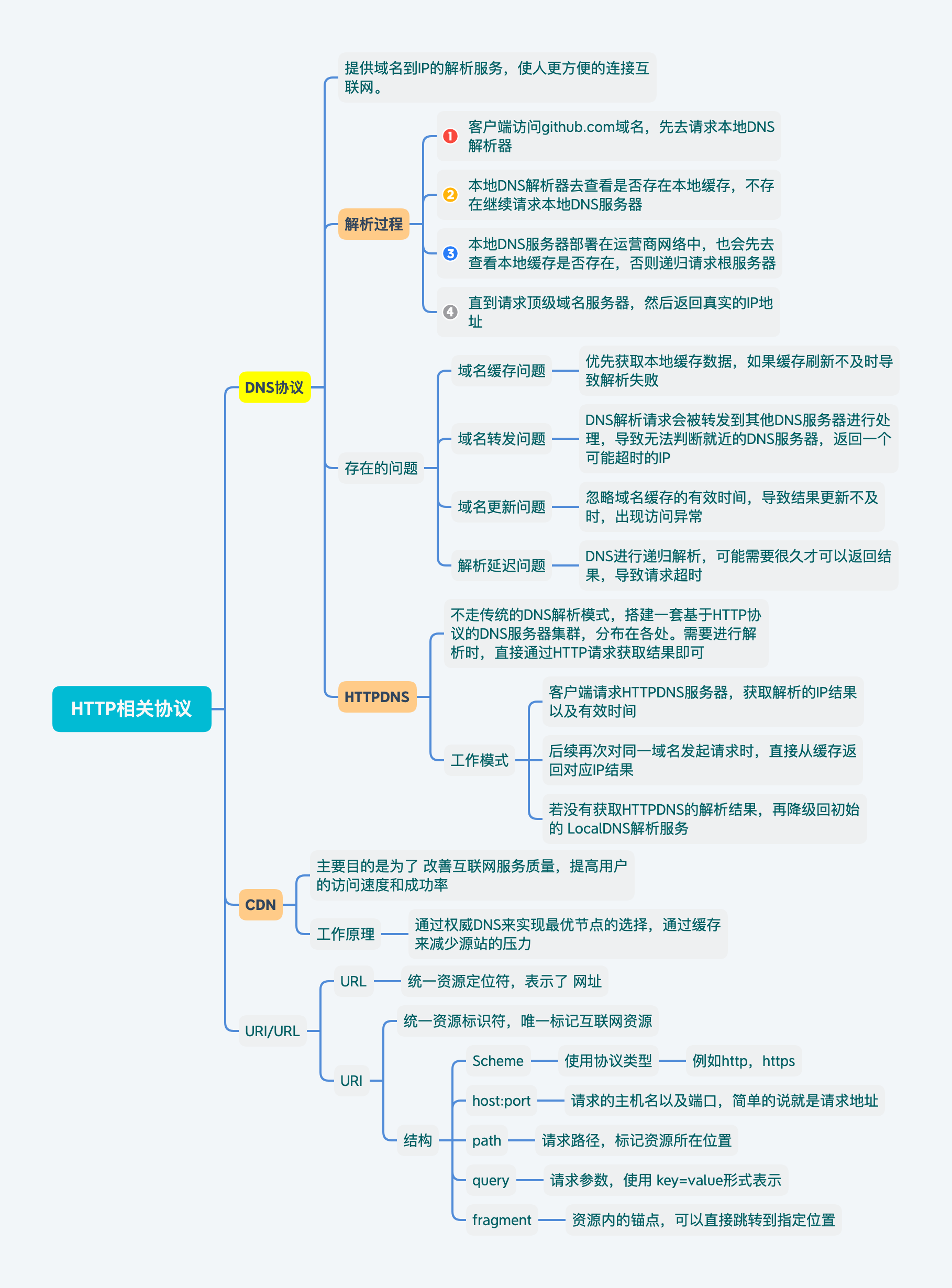
DNS协议
提供域名到IP地址之间的解析服务,能够使人更方便地访问互联网。
还可以根据多个地址做负载均衡,并且选择一个就近的地点IP进行访问。
解析过程
- 客户端访问
XX.com域名,先去请求本地DNS解析器 - 本地DNS解析器先去查看本地缓存是否有对应记录,若有直接使用;否则请求本地DNS服务器
- 本地DNS服务器一般部署在运营商网络中,然后本地DNS服务器也会查看是否存在本地缓存,存在则直接使用;否则递归请求根服务器
- 直到请求到顶级域名服务器,例如
.com,查到数据后返回真实的IP地址。
存在的问题
域名缓存问题
由于DNS会优先获取本地缓存,如果缓存没有及时刷新,就会导致访问失败。
域名转发问题
DNS解析请求可能会被转发到其他DNS服务器进行处理,导致解析时无法判断地址,而返回一个较远IP使访问异常。
域名更新问题
忽略域名缓存IP的有效时间,导致结果更新不及时,一样会有访问异常问题
解析延迟问题
DNS会进行递归解析,可能经过多个服务器,才可以获得最终结果,中间时间非常漫长
HTTPDNS
不走传统的DNS解析模式,自己搭建基于HTTP协议的DNS服务器集群,分布在多个地点和多个运营商。需要进行DNS解析时,直接通过HTTP请求这个集群得到结果即可。
工作模式
在客户端动态请求HTTPDNS服务端,获取解析的IP结果以及失效时间缓存到本地。后续在缓存未失效的情况下可直接返回对应域名的IP信息。如果没有返回信息,也可以降级回最初的LocalDNS解析方案。
CDN
内容分发网络(Content Delivery Network)。主要目的是改善互联网服务质量,提高用户访问网站的响应速度和成功率。
通过权威DNS服务器来实现最优节点的选择,通过缓存来减少源站的压力
URL/URI
用户在浏览器地址栏输入的或者是App发起请求时设置的地址
URI:统一资源标识符,唯一的标记互联网资源
URL:统一资源定位符,也就是网址,实际为URI的子集
URI结构

协议类型(scheme)
比如http,https,file等,必须和://连在一起
服务器地址(host:port)
对应的是所需接受浏览器/App请求的服务器地址
请求路径(path)
对应请求需要处理的位置
查询参数(query)
为key=value这类的形式,存在多个用&进行连接
锚点(fragment)
表示URI定位资源内的一个锚点,通过这个锚点可以跳转到指定位置
1 | |
参考链接