Java-BlockingQueue阻塞队列
Queue接口
Queue队列的特征是FIFO——先进先出。只有队尾可以进行插入操作,只有队头可以进行删除操作。
Java中的Queue继承了Collection接口,并额外实现了以下方法
1 | |
队列插入数据操作(add/offer)
将新数据插入队尾
add:如果队列满时,插入队尾数据,就会抛出IllegalStateExecption
offer:如果队列满时,插入队尾数据,不会抛出异常,会返回false
队列删除数据操作(remove/poll)
获取队头元素并删除
remove:当队列为空时,删除元素时,会抛出NoSuchElementException
poll:当队列为空时,删除元素时,不会抛出异常,只会返回null
队列检查数据操作(element/peek)
获取队头元素但并不删除
element:当队列为空时,获取队头元素,会抛出NoSuchElementException
peek:当队列为空时,获取队头元素,不会抛出异常,只会返回null
| 抛出异常 | 特殊值 | |
|---|---|---|
| 插入 | add() |
offer() 返回 false |
| 删除 | remove() |
poll() 返回null |
| 获取数据(检查) | element() |
peek() 返回null |
如果把队列相关方法放在一起看,可以先形成一个统一认知:
- 异常型:失败时直接抛异常,适合把“当前操作一定要成功”视为前提的场景
- 特殊值型:失败时返回
null/false,适合调用方自己决定后续分支
后面的BlockingQueue其实是在这套方法体系上,继续扩展出了阻塞型和超时型两类操作。
BlockingQueue接口
系统提供的用于多线程环境下存、取共享变量的一种容器。
BlockingQueue阻塞队列实现了Queue接口,相比于Queue提供了额外的功能:
- 获取队头元素时,如果队列为空,执行线程会处于阻塞状态,直到队列非空——
对应删除和检查操作 - 添加队尾元素时,如果队列已满,执行线程会处于阻塞状态,直到队列不满——
对应插入操作
当触发上述两种情况的出现时,按照不同的设置方式,提供了以下几种处理方案:
- 抛出异常
- 返回特殊值(返回
null或false) - 阻塞当前线程直到可以执行
- 阻塞线程设置最大超时时间,若超过该时间,线程就会继续执行,放弃当次操作
因此从方法家族的角度看,BlockingQueue其实可以统一理解成四类语义:
- 异常型:
add/remove/element - 特殊值型:
offer/poll/peek - 阻塞型:
put/take - 超时型:
offer(time)/poll(time)
不过也要注意:BlockingQueue解决的是生产者-消费者之间的协作问题,并不等于“只要用了阻塞队列就天然高并发”。不同实现类在锁粒度、容量模型和吞吐特征上差异很大。
阻塞队列插入数据操作(put/offer(time))
对应阻塞队列在队列已满插入数据时的
阻塞或者超时处理
put:如果队列满时,插入队尾数据,会阻塞当前线程直到队列非满
offer(time):如果队列满时,插入队尾数据,会阻塞当前线程直到队列非满或者达到了超时时间,达到超时时间则返回false
这两个方法都可能在等待过程中被中断,因此都需要正确处理InterruptedException,而不是默认认为“阻塞就一定会一直等到成功”。
阻塞队列删除数据操作(take()/poll(time))
对应阻塞队列在队列为空时获取数据时的
阻塞或超时处理
take():当队列为空时,删除元素时,会阻塞当前线程直到队列非空
poll(time):当队列为空时,删除元素时,会阻塞当前线程直到队列非空或者达到了超时时间,达到超时时间返回null
同样地,take()和poll(time)也都需要面对中断语义:线程如果在等待过程中被中断,当前阻塞操作会提前结束。
阻塞队列检查数据操作
| 抛出异常 | 特殊值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add() |
offer() 返回 false |
put() |
offer(time)返回false |
| 删除 | remove() |
poll() 返回null |
take() |
poll(time)返回null |
| 获取数据(检查) | element() |
peek() 返回null |
/ | / |
注意点
- 阻塞队列无法插入
null,否则抛出空指针异常 - 可以访问阻塞队列中的任意元素,尽量避免使用
remove(object)移除对象 - 不要轻易使用
size()做并发控制判断,因为在多线程场景下它更适合观察状态,而不是作为强一致业务条件
BlockingQueue实现类
在Java-线程池中的workQueue设置的就是BlockingQueue接口的实现类,
例如
ArrayBlockingQueue:数组构成的有界阻塞队列LinkedBlockingQueue:链表构成的有界阻塞队列,如果不设置大小的话,近似无界阻塞队列SynchronousQueue:不存储任何元素的阻塞队列PriorityBlockingQueue:支持优先级排序的无界阻塞队列
BlockingQueue原理
BlockingQueue只是一个接口,真正的实现都是在XXBloxckingQueue中的,想要分析对应的原理就需要从实现类进行分析
ArrayBlockingQueue
由数组实现的有界阻塞队列,大小一旦确定就无法改变队列的长度。
关键成员变量
1 | |
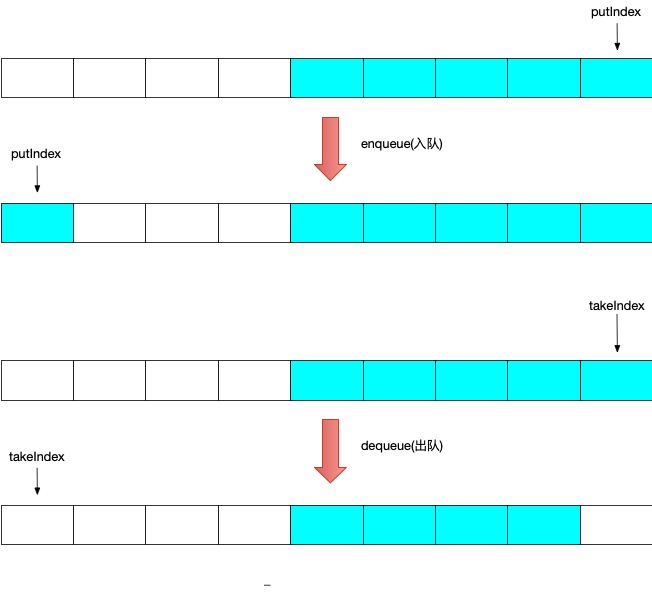
ArrayBlockingQueue阻塞功能的实现就是依赖了ReentrantLock以及Condition实现了等待机制。
构造函数
1 | |
capacity:设置阻塞队列的数组容量
fair:设置线程并发是否公平(默认配置非公平锁)
当前锁被一个线程持有时,其他线程会被挂起等待锁的释放,等待时加入等待队列。
公平锁:当锁释放时,等待队列的前端线程会优先获取锁
非公平锁:当锁释放时,等待队列中的所有线程都会去尝试获取锁
在ArrayBlockingQueue初始化时,构造ReentrantLock锁以及两个Condition对象控制数据插入、删除时的阻塞。
实现方法
offer() 非阻塞添加数据
1 | |
offer()添加数据时,将当前线程上锁。
- 在当前队列已满时,直接返回
false - 当前队列未满时,调用
enqueue()添加数据,putIndex设置对应数据且putIndex++。 然后通知阻塞的消费线程notEmpty
poll() 非阻塞取出数据
1 | |
poll()取出数据时,将当前线程上锁
- 当前队列为空的时候,直接返回null
- 当前队列非空的时候,调用
dequeue()将takeIndex元素出队,设置takeIndex处元素为null且takeIndex--。然后通知阻塞的生产线程notFull
offer(time)不超时阻塞添加数据
1 | |
offer(time)添加数据时,将当前线程上锁
- 在当前队列已满时,阻塞生产线程
notFull,超过time后,队列还是满的话,直接返回false - 当前队列未满时,调用
enqueue()添加数据,putIndex设置对应数据且putIndex++。 然后通知阻塞的消费者notEmpty
poll(time)不超时阻塞取出数据
1 | |
poll(time)取出数据时,将当前线程上锁
- 当前队列为空的时候,阻塞消费线程
notEmpty,超过time后,队列还是空的话,直接返回null - 当前队列非空的时候,调用
dequeue()将takeIndex元素出队,设置takeIndex处元素为null且takeIndex--。然后通知阻塞的生产者notFull
put()阻塞添加数据
1 | |
put()添加数据时
- 当前队列已满时,阻塞当前线程,等待
notFull通知(队列未满) - 当前队列未满时,调用
enqueue()添加数据,putIndex设置对应数据且putIndex++。 然后通知阻塞的消费者notEmpty
take()阻塞获取数据
1 | |
take()获取数据时
- 当前队列为空时,阻塞当前线程,等待
notEmpty通知(队列新增数据) - 当前队列非空的时候,调用
dequeue()将takeIndex元素出队,设置takeIndex处元素为null且takeIndex--。然后通知阻塞的生产者notFull
其中Condition的await/signal类似于Object的wait/notify实现等待与通知的功能。
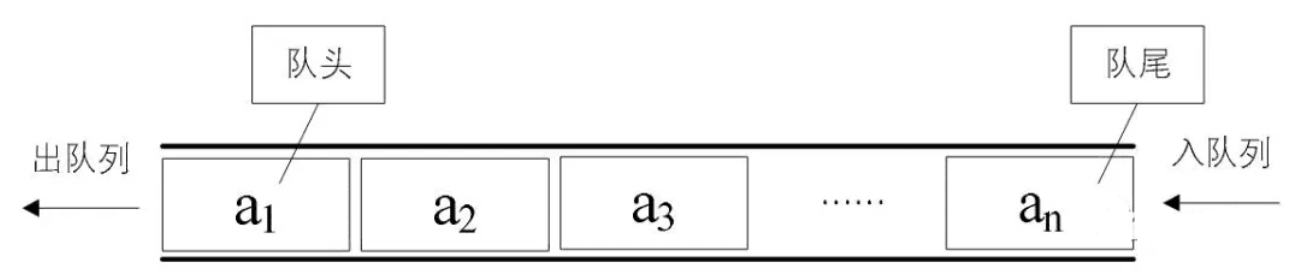
在分析enqueue()和dequeue()时,发现底层数组不会进行扩容,而是在到达边缘时,重置index为0,重复利用数组。
从上述源码对ArrayBlockingQueue进行总结:
底层数据结构是一个 数组,生产者和消费者由同一个锁(ReetrantLock)控制,生产和消费效率低。
如果再概括得更完整一点,ArrayBlockingQueue有三个非常鲜明的特征:
- 有界:容量固定,天然具备背压能力
- 单锁:生产和消费会共享同一把锁,竞争更集中
- 循环数组:内存结构紧凑,不需要为每个元素额外创建链表节点
因此它更适合:希望明确限制队列容量、控制内存上界,并接受生产消费存在更多互斥的场景。
LinkedBlockingQueue
由链表实现的阻塞队列,默认最大长度为
Integer.MAX。
关键成员变量
1 | |
LinkedBlockingQueue采用了两把锁putLock、takeLock,分别进行控制,提高了并发性能。
构造函数
1 | |
capacity:设置单链表长度上限,若不设置该值,默认为Integer.MAX
构造函数初始化了底层的链表结构。
实现方法
offer()非阻塞添加数据
1 | |
offer添加数据时,当队列已满时,直接返回false。未满时,插入新数据后,count自加后唤醒notFull、notEmpty。
poll()非阻塞获取数据
1 | |
poll获取数据时,队列为空时,直接返回null。队列非空时,获取数据后,数据出队,count自减后,先后唤醒notEmpty、notFull。
put()阻塞添加数据
1 | |
put()添加数据时,队列已满时,会进行阻塞等待直到队列非满。
take()阻塞获取数据
1 | |
take()获取数据时,队列为空时,会进行阻塞等到直到队列非空。
从上述源码对LinkedBlockingQueue进行总结:
LinkedBlockingQueue底层数据结构为单链表,内部持有两个Lock:putLock、takeLock,相互之间不会干扰执行,提高了并发性能。
如果从使用角度总结,LinkedBlockingQueue还有几个关键特征:
- 默认容量近似无界,如果不显式指定大小,任务和数据可能持续堆积
- 由于生产和消费拆成两把锁,吞吐通常会优于单锁队列
- 链表节点需要额外对象开销,内存占用通常会比数组队列更高
与ArrayBlockingQueue比较
| ArrayBlockingQueue | LinkedBlockingQueue | |
|---|---|---|
| 构造方法 | 必须指定构造大小 指定后无法修改 |
默认大小为Integer.MAX可以指定大小 |
| 底层数据结构 | 数组 | 单链表 |
| 锁 | 出队入队使用同一把锁 数据的删除和添加操作互斥 |
出队使用takeLock,入队使用putLock数据删除、添加操作不干扰,提升并发性能 |
如果从实际选型角度来记会更直接:
- 想要明确容量上限、天然背压、稳定内存占用,优先考虑
ArrayBlockingQueue - 想要更灵活的容量和更高的并发吞吐,可以考虑
LinkedBlockingQueue - 但线程池里如果直接使用默认无界
LinkedBlockingQueue,要特别小心任务无限堆积导致内存风险
SynchronousQueue
容量为0,无法储存数据的阻塞队列。提供了公平与非公平锁的设置。
这里最容易误解的一点是:SynchronousQueue并不是“容量为1”,而是真正意义上的容量为0。它不会把元素放进内部容器里等待后续消费,而是要求每一次生产都要和一次消费直接配对完成,属于一种**直接移交(handoff)**机制。
关键成员变量
1 | |
构造函数
1 | |
实现方法
数据操作offer()/poll() put()/take()
1 | |
上述的数据操作方法都涉及到了两部分内容:
transferer:数据调度transfer:数据执行
TransferQueue
SynchronousQueue的公平实现,内部实现使用队列,可以保证先进先出的特性。
基本实现方法:
当前队列为空的时候或者存在了与即将添加的QNode操作模式一致(isData一致)的节点,线程进行同步等待,QNode添加到队列中。
继续等待与队列头部QNode操作互补(写操作(isData = true),等待一个读操作(isData = false))的QNode节点
新添加的QNode节点与队头QNode操作互补时,尝试通过CAS更新等待节点的item字段,然后让队头等待节点出列,并返回节点元素和更新队头节点。
如果队列中的节点的waiter等待线程被取消,节点也会被清理出队列。
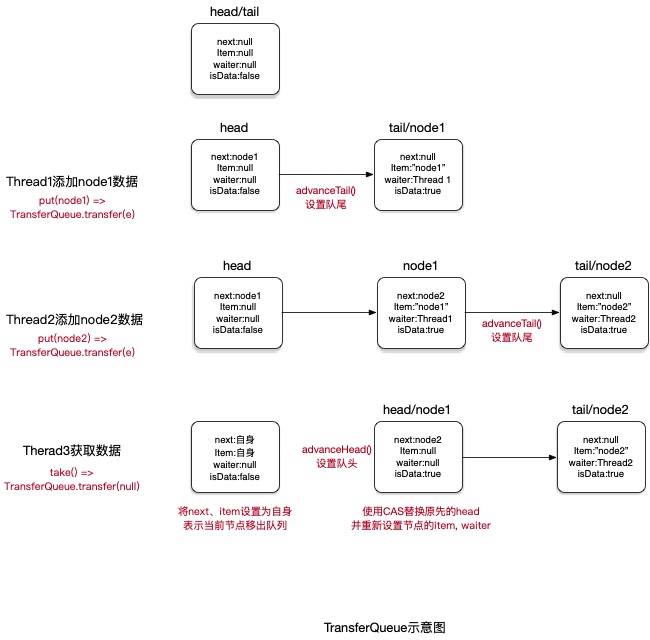
isData:true 表示put操作,false表示take操作。
next:下一个节点
waiter:当前等待的线程
item:元素信息
TransferStack
SynchronousQueue非公平实现,内部实现使用栈,实现了先进后出的特性。
基本实现方法:
当前栈为空或者存在了与即将添加的SNode模式相同的节点(mode一致),线程进行同步等待,SNode添加到栈中
继续等待与栈顶SNode操作互补(写操作(mode = DATA),读操作(mode=REQUEST))的节点
出现与栈顶SNode操作互补的节点后,新增SNode节点的mode会变为FULFILLING,与栈顶节点匹配,匹配完成后,将俩节点都弹出并返回匹配节点的结果。
如果栈顶元素找到匹配节点,就会继续向下帮助匹配(此时上一个匹配操作还没结束又进入一个新的请求)
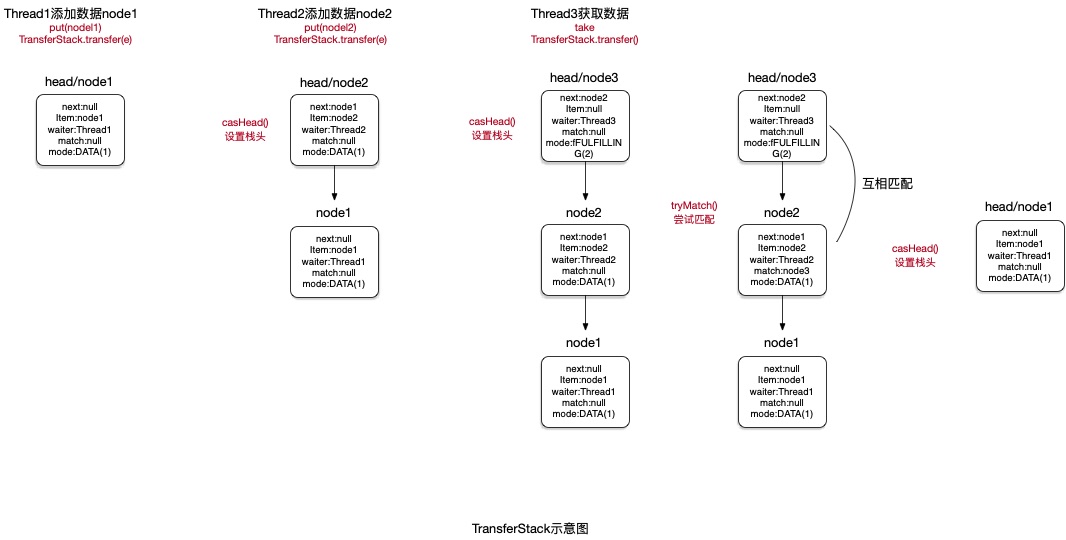
next:下一个元素
item:元素信息
waiter:当前等待的线程
match:匹配的节点
mode:DATA(1)-添加数据、REQUEST(0)-获取数据、FULFILLING(2)-互补模式
特点
SynchronousQueue容量为0,无法进行数据存储- 每次写入数据时,写线程都需要等待;直到另一个线程执行读操作,写线程会返回数据。写入元素不能为null
peek()返回null;size()返回0;无法进行迭代操作- 提供了
公平,非公平两种策略处理,分别是基于Queue-TransferQueue与Stack-TransferStack实现。
也正因为它不缓存元素,SynchronousQueue特别适合那种“任务不要排队,来了就直接找线程接手,否则就促使线程池扩容或触发拒绝策略”的场景。
原理介绍
绝大多数都是利用了Lock锁的多条件(Condition)阻塞控制。
拿ArrayBlockingQueue进行简单描述就是:
put和take操作都需要先获取锁,无法获取的话就要一直自旋拿锁,直到获取锁为止- 在拿到锁以后。还需要判断当前队列是否可用(
队列非满且非空),如果队列不可用就会被阻塞,并释放锁 - 阻塞的线程被唤醒时,依然需要在拿到锁之后才可以继续执行,否则,自旋拿锁,拿到锁继续判断当前队列是否可用(使用while判断)
使用场景
生产-消费模型
1 | |
线程池
Java-线程池BlockingQueue在线程池中的作用,不只是“把任务存起来”这么简单,它会直接影响线程池的行为策略:
- 使用
LinkedBlockingQueue时,任务更容易先排队,线程数往往不容易继续扩到maximumPoolSize - 使用
ArrayBlockingQueue时,队列容量有限,任务堆积到一定程度后更容易促使线程池扩容 - 使用
SynchronousQueue时,由于队列本身不缓存任务,任务提交更像直接交给工作线程处理,因此更容易触发线程数扩张
也就是说,线程池中的workQueue本质上决定的是:任务优先排队、优先扩容,还是优先直接移交。
拓展知识
常见误用与风险
- 误把无界
LinkedBlockingQueue当成“安全默认值”,结果在高峰时持续堆积任务 - 在不合适的线程中直接调用
put()/take(),导致主线程、核心业务线程被阻塞 - 忽略
InterruptedException,导致线程无法优雅退出 - 依赖
size()来做严格并发判断,结果和真实队列状态产生竞态 - 使用
remove(object)这类按值删除操作,导致额外遍历成本和并发语义复杂化
所以从工程实践上看,BlockingQueue更适合承担削峰、缓冲、解耦、等待协作这些职责,而不是作为“随便塞任务进去总没问题”的万能容器。
与其他队列的区别
BlockingQueue:强调阻塞协作,适合生产者-消费者模型ConcurrentLinkedQueue:强调非阻塞并发访问,不提供put/take这类等待能力Deque:强调双端操作语义,是否阻塞要看具体实现
因此选型时最好先问自己:当前需求到底是要阻塞等待、要高并发无锁访问,还是要双端操作能力,再决定是不是应该上BlockingQueue。
Guarded Suspension(保护性暂时挂起)
当服务进程准备好时,才提供服务。
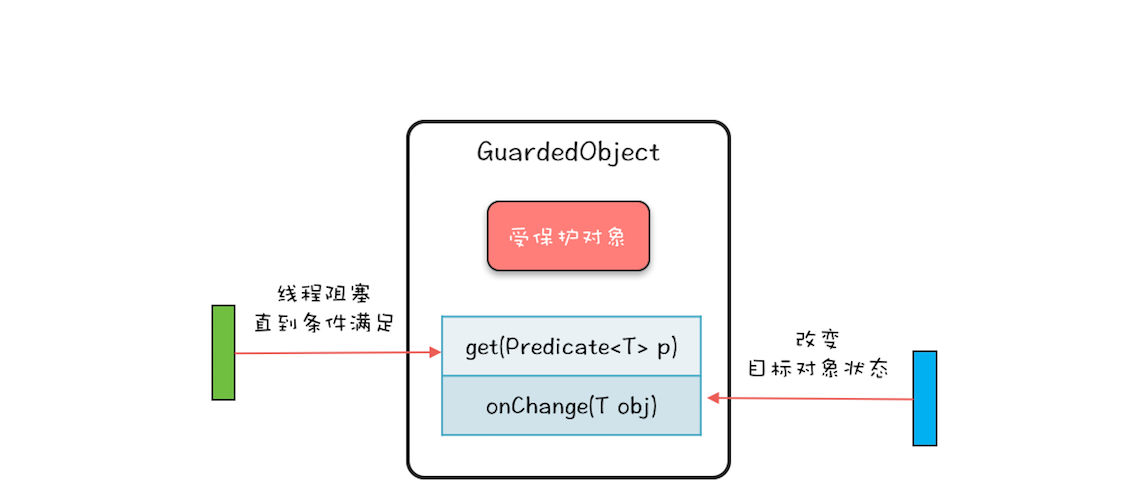
本质是一种等待唤醒机制的实现,也称为多线程的if
基本实现代码
1 | |